My name is Jiuxiang Gu (顾久祥). I am a Senior Research Scientist at Adobe Research in Seattle. I received my Ph.D. from Nanyang Technological University, Singapore (2016.1–2019.5), under the supervision of Prof. Jianfei Cai, Dr. Gang Wang, and Prof. Tsuhan Chen. My research journey began in hardware design. From 2010 to 2015, I worked as a hardware engineer (ASIC, FPGA, and PCB design). In 2015, I made the transition to Artificial Intelligence.
My current research focuses on multimodal foundation models, efficient AI, reasoning, and document intelligence.
Outside of research, I enjoy hiking and exploring the outdoors, as well as 3D printing, painting, and designing and building robots.
Open to collaborations and internships in the above areas.
Latest Updates
All updates-
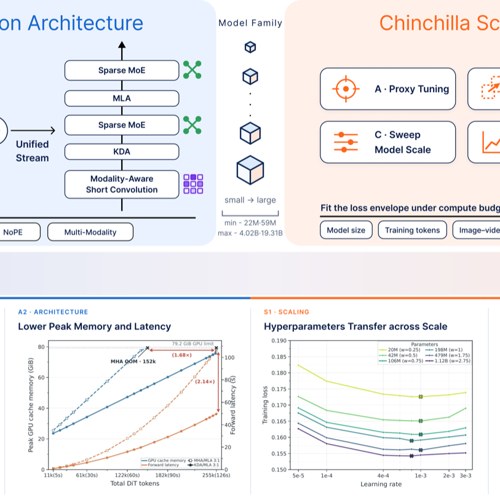
Chimera, our hybrid visual diffusion transformer with a Chinchilla-style scaling recipe, is now available.
-
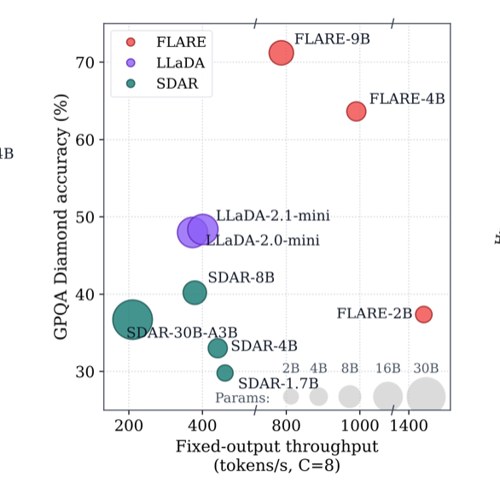
FLARE, our framework for converting hybrid autoregressive models into diffusion language models, is now available.
-
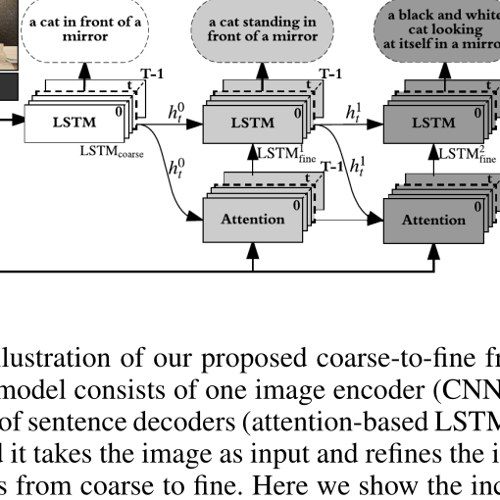
LaViDa-O, our unified diffusion model for multimodal understanding and generation, appears at ICLR 2026.
-
LaViDa-R1, our reasoning model for unified multimodal diffusion, appears at ICML 2026.
-
Sparse-LaViDa, our efficient sparse multimodal diffusion model, appears at CVPR 2026.
-
FastCar, our work on efficient autoregressive video generation for edge devices, appears at ICLR 2026.
Selective Works
2026

2025
2024
2021
2018
-
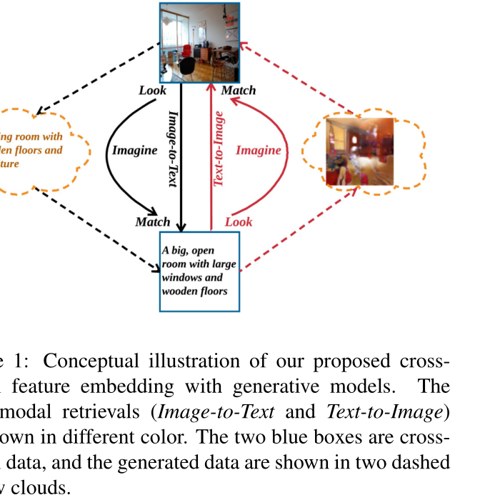 CVPR 2018Look, Imagine and Match: Improving Textual-Visual Cross-Modal Retrieval with Generative Models
CVPR 2018Look, Imagine and Match: Improving Textual-Visual Cross-Modal Retrieval with Generative Models -